Un informe identificó más de 16.800 insultos de Milei en X desde que asumió la Presidencia
Un informe del Foro de Periodismo Argentino (Fopea) difundido este jueves identificó que, desde su asunción en diciembre de 2023, el presidente argentino, Javier Milei, publicó más de 16.800 mensajes con insultos en la red social X.
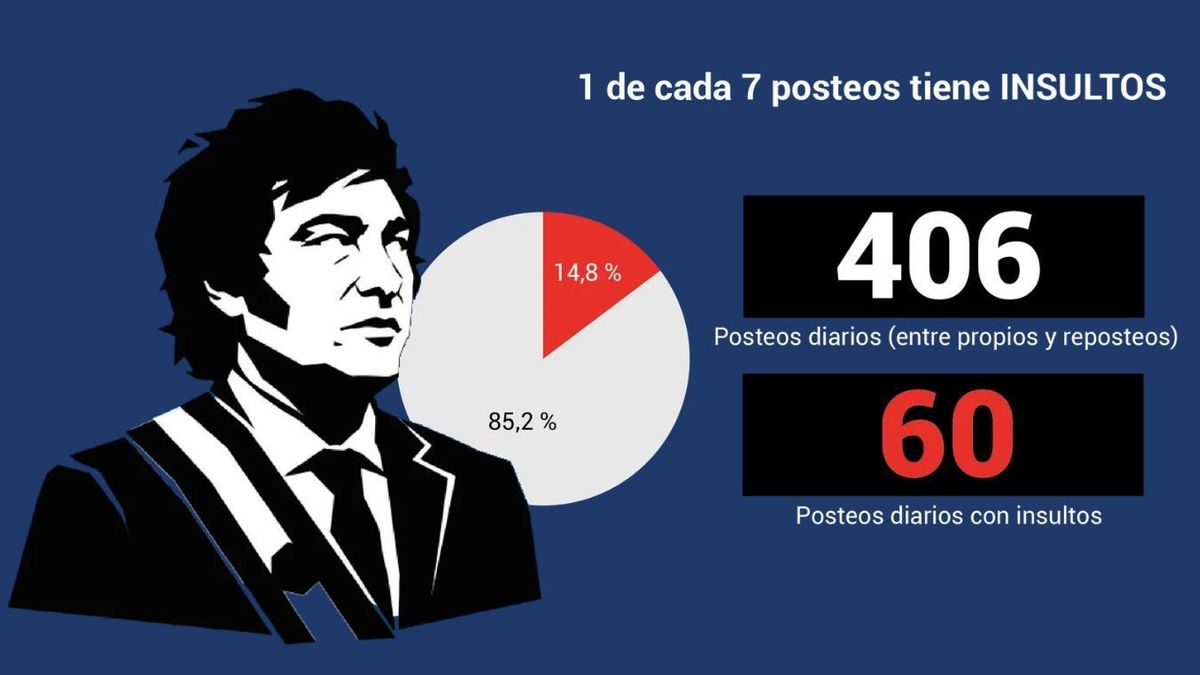
De acuerdo con el estudio, titulado 'El insulto como estrategia' y que analizó más de 113.000 publicaciones de Milei en X entre su asunción el 10 de diciembre de 2023 y el pasado 15 de septiembre, uno de cada siete posteos del mandatario contienen expresiones insultantes, despectivas o estigmatizantes dirigidas a personas, empresas y entidades. Entre ellas al menos 62 periodistas y 14 medios de comunicación.
El trabajo, que enfatizó que Milei publica en promedio 60 posteos diarios con insultos, fue realizado por el Data Journalism Visualization Bootcamp (DJV) de Fopea y destacó que el presidente utiliza el insulto como parte central de su estrategia de comunicación en X desde su asunción.
“La llegada de Javier Milei a la arena pública, primero como panelista televisivo y líder de opinión, luego como diputado nacional y finalmente como presidente, marcó el inicio de una forma de comunicación plagada de insultos hacia quien piensa diferente”, subrayó Fopea.
El análisis identificó cinco grandes categorías de insultos: despectivos, estigmatizantes, de animalización, repulsivos y sexualizados. El insulto más utilizado fue “kuka”, una forma despectiva de referirse a los kirchneristas comparándolos con cucarachas, que utilizó en 2.286 menciones.

“Cuando el insulto se vuelve estrategia y el algoritmo lo premia, el debate público se degrada, crece la autocensura y se apagan voces”, añadió Fopea, que identificó que el 70 % de los tuits dirigidos a actores del campo mediático contenían términos despectivos o estigmatizantes.
“La figura presidencial, por su peso en sí misma, facilita la amplificación del mensaje. Cada mensaje activa un enjambre de cuentas que repiten, insultan y logran una escalada de difusión”, agregó el informe, que advirtió que esto tuvo consecuencias en el ejercicio del periodismo: “Como consecuencia, la autocensura ganó terreno: en algunos casos se volvió un mecanismo de defensa”.
Para la elaboración del proyecto, un equipo interdisciplinario analizó tanto las publicaciones originales como reposteos del presidente y puso a disposición del público un buscador de insultos y las bases de datos utilizadas.
El informe detectó un patrón temporal en el uso de insultos: “Los picos de insultos coincidieron con anuncios económicos clave, mostrando cómo el conflicto y la agresión funcionan como herramientas de viralización”.
Periodistas y medios, blancos preferidos
La lista de periodistas y líderes de opinión atacados incluye a al menos 44 comunicadores: Alejandro Alfie, Baby Etchecopar, Carlos Pagni, Delfina Celichini, Diego Cabot, Diego Leuco, Diego Sehinkman, Eduardo Anguita, Ernesto Tenembaum, Facundo Pastor, Florencia Donovan, Galia Moldavsky, Hugo Alconada Mon, Ignacio Ortelli, Iván Ruiz, Iván Schargrodsky, Ivy Cángaro, Jairo Straccia, Jesica Bossi, Jonathan Heguier, Jorge Asís, Jorge Fernández Díaz, Jorge Fontevecchia, Jorge Lanata, Jorge Rial, Juan Bracco, Julia Mengolini, Luciana Geuna, Luciana Peker, Luciana Rubinska, Luis Novaresio, Marcelo Bonelli, Marcelo Longobardi, María Laura Santillán, María O'Donnell, Mónica Gutiérrez, Natasha Niebieskikwiat, Pablo Duggan, Roberto Navarro, Romina Manguel, Silvia Mercado, Tamara Pettinato, Úrsula Vargues y Víctor Hugo Morales.
En la misma muestra los medios atacados fueron Ámbito Financiero, BAE Negocios, C5N, Clarín, Crónica, Diario Popular, El Cronista, El Destape, La Nación, La Política Online, Olé, Página/12, Perfil y Revista Noticias, entre otros.
Metodología del informe
¿Cuál fue la fuente de datos que se usó para este trabajo?
Los datos que contienen los tuits y retuits del presidente Javier Milei se descargaron desde el sitio: milei-tuiter-trends (Ruta de tuits), retuits-milei (Ruta de retuits). Se recopiló el contenido entre el 10 de diciembre de 2023 y hasta el 15 de septiembre de 2025. Para el análisis de datos se descargaron ambas bases en formato CSV.
¿Qué procedimientos se realizaron para procesar los datos?
Para la limpieza y el procesamiento de datos se utilizó Python v. 3.12.12. De manera complementaria se usó Microsoft Excel v. 2021 para tareas de baja complejidad.
¿Cómo se identificaron los insultos en la base de datos de tuits?
La detección de insultos se realizó mediante un enfoque híbrido y multietapa de procesamiento de lenguaje natural, con el fin de poder capturar la mayor cantidad de insultos posibles, teniendo en cuenta que el discurso analizado presenta un uso intensivo de expresiones no estandarizadas, tales como palabras inventadas, deformaciones léxicas locales, apodos y construcciones creativas propias del contexto político y cultural argentino. El preprocesamiento de los textos se llevó a cabo con las librerías de python NLTK y spaCy, e incluyó la normalización del contenido (limpieza, eliminación de stopwords, etc), para generar una columna de texto reducida. Sobre este corpus se aplicó un diccionario de sentimiento en español para asignar puntajes de polaridad. Se seleccionaron aquellos con mayor score para el sentimiento “hate”, y de este subconjunto se extrajeron las palabras con mayor frecuencia. A partir de los términos identificados, se generaron de forma automática variantes lingüísticas para considerar diferencias de género y número (masculino, femenino y plural, ej. tonto, tonta, tontos), ampliando el alcance del diccionario. Luego, se utilizó un LLM (Large Language Model) de OpenAI (GPT-4o mini) para enriquecer más aún el conjunto de insultos, incorporando usos propios del español de Argentina. Finalmente, se realizó una etapa de curación manual, destinada a validar los resultados e identificar formas derivadas o inventadas (como deformaciones de palabras base: ej. periosobres, periokukas, etc) y apodos (Mandrilesio, Mandrelli, etc). Esta revisión manual no se limitó a considerar palabras sueltas en los textos originales, sino que evaluó el contexto en el que aparecían, asegurando que fueran efectivamente utilizadas como insultos, consolidando así el listado final de ofensas.
¿Cómo se clasificaron los insultos?
Se los categorizó en cinco clases: despectivos, con contenido sexual, estigmatizante, animalización del discurso y contenido repulsivo.
¿Qué tipos de análisis se realizaron sobre la base de datos?
Sobre la cantidad de tuits y retuits, calculó el porcentaje de los que contenían insultos sobre la base del total. También se estableció una línea de tiempo por mes, relacionando cantidad de tuits y retuits totales, cantidad de tuits y retuits con al menos un insulto y se calcularon porcentajes para cada mes.
¿Cómo se escribió la historia?
El trabajo se encuadra en lo que se conoce como periodismo de datos por lo que cada contenido está directamente relacionado con los datos que fueron debidamente obtenidos y procesados. Previamente se realizó un rastreo en la Web para poner en contexto el tema que nos ocupa. Luego se analizaron las hojas de cálculo que contenían los datos procesados que sirvieron para la narrativa. El método narrativo se apoyó en la premisa de explicar el significado de los datos. El desafío fue transformar un voluminoso y complejo conjunto de texto y números en una historia accesible para el público, usando análisis, visualizaciones y contextualización.
¿Cómo se resolvió el diseño de las ilustraciones?
El diseño visual y las ilustraciones desarrolladas para este informe constituyen un componente orientado a traducir un conjunto de datos complejos y sensibles en representaciones claras, accesibles y contextualizadas. Desde un enfoque de visualización de información aplicado al periodismo de datos, las decisiones gráficas se guiaron por criterios de legibilidad, sobriedad y coherencia narrativa, priorizando la identificación de patrones, recurrencias y dinámicas discursivas. El lenguaje visual adoptado —minimalista, de alto contraste y baja carga ornamental— busca evitar el sensacionalismo y reforzar el carácter analítico y documental como unidades de análisis cuantificadas y contextualizadas, integradas de manera orgánica a la narrativa del informe.
Créditosdel Informe
Investigación Periodística: Sandra Crucianelli / Procesamiento y visualización de datos: Rosa Morales / Diseño y análisis de datos: Natalia Gorbarán / Desarrollo: Nicolás Rivera y Ramón Gutierrez / Mentoría: Andrés Snitcofsky / Liderazgo de DJV Bootcamp: Irene Benito / Supervisión de FOPEA: Amelia Corazza (directora ejecutiva) y Paula Moreno Román (secretaria) / Coordinación de Comunicación: Sol Clemente.
Con información de FOPEA y EFE

0